Here at Mozilla, we are tirelessly working to bring our products to a global audience. Pontoon, our in-house translation management system plays a central role, where volunteer localizers work to bring translations for Firefox, Thunderbird, SUMO and other Mozilla products.
Recently, we have been working to unify localization tools and give localizers and developers smoother, more streamlined workflows. This is why we are excited to introduce Pontoon’s new Translation Search feature, where everyone can search for strings across all projects and locales at Mozilla.
What is the Translation Search Feature?
Translation Search is Pontoon’s latest way to access our extensive collection of translations, built up through years of localization work by fellow Mozillians. This new feature allows localizers to search for strings across all projects and all locales at Mozilla. Inspired by the functionality of Transvision, it is intended to be a suitable replacement and includes many of the various features that localizers rely on.
Let’s go through some of its features and how they can apply to your localization workflows.
Searching for Translations
Pontoon’s new Translation Search, where users can search for strings through all projects and locales.
Searching for strings in Translation Search is simple. Similar to how Transvision operates, you can search within a specific project and locale, as well as filter by string identifiers, case sensitivity and whole word search. Unlike Transvision, Pontoon Translation Search covers all products localized at Mozilla. It is also completely integrated with other Pontoon elements, including Translate, such that you can seamlessly navigate to Translate after your search.
Transvision’s search functionality, which we intend to replace.
Finding Entity Translations
Pontoon’s new Entity Translations page, which lists available translations for a source string.
If you want to get a better picture of a source string with different translations, go to the Entity Translations page. By clicking the “All Locales” button in Translation Search for a string, you can see the source string translated into every available locale. This is useful for comparing similar locale translations and getting a broader picture of a string’s context. This feature is intended to replace Transvision’s translation list for a particular entity.
Transvision’s string translation list, which we intend to replace.
Searching from Firefox Address Bar
If you have the Pontoon Add-on installed to the latest version, you can now search for strings directly from the address bar in Firefox: you can select Pontoon from the list of search engines, or start typing pontoon and press TAB.
How to use Translation Search with Pontoon Add-on.
Pontoon Translation Search is Live!
This feature is available now and ready for you to use. Head over to pontoon.mozilla.org/search to try out the new search experience and streamline your localization work! If you have any questions or concerns about Translation Search, do not hesitate to contact us on Matrix or file an issue. You can also consult the documentation here.
My name is Oliver Chan, though I am mostly known by my username Olvcpr423. I’m from China, and I speak Mandarin and Cantonese. I have been contributing to Mozilla localization in Simplified Chinese since 2020.
Getting Started
Q: How did you first get involved in localization, and what led you to Mozilla?
A: My localization journey actually began with Minecraft back in 2018, when I was 13. I was an avid player of this globally popular game. Similar to Mozilla, its developer uses a crowdsourcing platform to let players localize the game themselves. I joined the effort and quickly realized that I had a strong interest in translation. More importantly, I found myself eager to use my skills to help bridge language gaps, so that more people could enjoy content from different languages easily.
Firefox was the first Mozilla product I ever used. I started using it relatively late, in 2020, and my connection with Firefox began thanks to my uncle. Although I was aware that Firefox had a long history, I didn’t yet understand what made it special. I gradually learned about its unique features and position as I explored further, and from then on, Firefox became my primary browser.
Later that same year, I noticed a typo while using Firefox and suggested a fix on Pontoon (I honestly can’t recall how I found Pontoon at the time). That small contribution marked the beginning of my journey as a Mozilla localizer. I believe many people’s localization journeys also start by correcting a single typo.
Working on Mozilla Products
Q: Which Mozilla projects do you enjoy working on the most, and why?
A: Firefox, absolutely. For one thing, it’s my favorite piece of software, which makes working on it personally meaningful. More importantly, Firefox has a massive Chinese user base, which gives me a strong sense of responsibility to provide the best possible language support for my fellow speakers. On top of that, Firefox’s mission as the last independent browser gives me extra motivation when working on its localization.
Aside from Firefox, Common Voice has been the most impactful project I’ve localized for Mozilla. It collects voices from a diverse range of speakers to build a publicly available voice dataset, which I think is especially valuable in this era. And honestly, working on the text for a voice-collection platform is a wonderful experience, isn’t it? 😀
Thunderbird is another project I find especially rewarding. It is popular on Linux, and localizing it means supporting many users who rely on it for everyday communication, which I consider vital work.
Q: How does regularly using these products influence how you approach localization?
A: Regular usage is essential for localization teams (like us) that lack dedicated LQA processes and personnel. Without routinely using the product, it’s easy to overlook issues that only become apparent in context, such as translations that don’t fit the context or layout problems.
Since we also lack a centralized channel to gather feedback from the broader community, we have to do our best to identify as many issues as we can ourselves. We also actively monitor social media and forums for user complaints related to localization. In addition, whenever I come across a screenshot of an unfamiliar interface, I take it as an opportunity to check for potential issues.
Community & Collaboration
Q: How does the Chinese localization community collaborate in practice?
A: In practice, besides myself, there is only one other active member on Pontoon for our locale. While the workload is still manageable, we do need to seriously think about recruiting new contributors and planning for succession to ensure sustainability.
That said, our community is larger than what you see on Pontoon alone. We have a localization group chat where many members stay connected. Although they may not actively contribute to Pontoon — some work on SUMO or MDN, some are regular users, while others are less active nowadays — I can always rely on them for insightful advice whenever I encounter tricky issues or need to make judgment calls. Oftentimes, we make collective decisions on key terminology and expressions to reflect community consensus.
Q: How do you coordinate translation, review, and testing when new strings appear?
A: Recently, our locale hit 60,000 strings — a milestone well worth celebrating. Completing the translation of such a massive volume has been a long-term effort, built on nearly two decades of steady, cumulative work by successive contributors. I’d like to take this opportunity to thank each and every one of them.
As for coordination, we don’t divide work by product — partly because all products already have a high completion level, and the number of products and new strings is still manageable. In practice, we treat untranslated strings a bit like Whac-A-Mole: whenever new strings appear, anyone available just steps in to translate them. Testing is also a duty we all share.
For review, we follow a cross-review principle. We avoid approving our own suggestions and instead leave them for peers to review. This helps reduce errors and encourages discussion, ensuring we arrive at the best possible translations.
Q: Did anyone mentor you when you joined the community, and how do you support new contributors today?
A: When I first joined Mozilla localization, I wasn’t familiar with the project’s practices or consensus. The locale manager 你我皆凡人 helped me greatly by introducing them. For several years, they were almost the only active proofreader for our locale, and I’d like to take this opportunity to pay tribute to their long-term dedication.
Today, when reviewing suggestions from newcomers, if a translation doesn’t yet meet the approval standard, I try my best to explain the issues through comments and encourage them to keep contributing, rather than simply rejecting their work — which could easily discourage them and dampen their enthusiasm.
Q: What do you think is most important for keeping the community sustainable over time?
A: It’s all about the people. Without people, there is no community. We need fresh blood to ensure we don’t face a succession crisis. At the moment, recruiting from within the Mozilla ecosystem (MDN or SUMO) is the most immediate approach, but I won’t give up on trying to draw in more people from the broader community.
Continuity of knowledge is also important. We mentor newcomers so they understand how the project works, along with its best practices and historical context. Documentation becomes necessary as time passes or the community grows; it ensures knowledge is preserved over time and prevents “institutional amnesia” as people come and go.
Background, Skills & Personal Lens
Q: What’s your background outside localization, and how does it shape your approach to translation?
A: I’m currently a student majoring in accounting. While accounting and software localization may seem worlds apart, I believe they share similar characteristics. The IFRS (International Financial Reporting Standards) identifies six qualitative characteristics of accounting information, and with a slight reinterpretation, I find that they also apply surprisingly well to localization and translation. For example:
Relevance: translations should help users use the product smoothly and as expected
Faithful representation: translations should reflect the original meaning and nuance, without being constrained by literal form
Verifiability: translations should be reasonable to any knowledgeable person
Timeliness: translations should be delivered promptly
Understandability: translations should be easy to comprehend
Comparability: translations should stay consistent with existing strings and industry standards
On a personal level, I developed qualities like prudence and precision through localization long before I started my degree, which gave me a head start in accounting. In turn, what I’ve learned through my studies has helped me perform even better in localization. It’s a somewhat interesting interplay.
Q: Besides translation, what else have you gained through localization?
A: I knew very little about Web technologies before I started localizing for Mozilla. Through working on Firefox localization, I gradually developed a solid understanding of Web technologies and gained deeper insight into how the Web works.
Fun Facts
Q: Any fun or unexpected facts you’d like to share about yourself?
A: My connection with Firefox began thanks to my uncle. One day, he borrowed my computer and complained that Firefox wasn’t installed — it had always been his go-to browser. So I decided to give it a try and installed it on my machine. That was how my journey with Firefox began.
I love watching anime, especially Bocchi the Rock! and the band Kessoku Band featured in the series. I also enjoy listening to Anisongs and Vocaloid music, particularly songs voiced by Hatsune Miku and Luo Tianyi. And while I enjoy watching football matches, I’m not very good at playing football myself!
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
Happy New Year!
What’s new or coming up in Firefox desktop
Preferences updates for 148
A new set of strings intended for inclusion in the preferences page of 148 landed recently in Pontoon on January 16. These strings, focused around controls of AI features, landed ahead of the UX and functionality implementation so are not currently testable. These should be testable within the coming week in Nightly and Beta.
Split view coming in 149
A new feature, called “split view”, is coming to Firefox 149. This feature and its related strings have already started landing at the end of 2025. You can test the feature now in Nightly, just right click a tab and select “Add Split View”. (If the option isn’t showing in your Nightly, then open about:config and ensure “browser.tabs.splitView.enabled” is set to true.
What’s new or coming up in mobile
Android onboarding testing updates
It is now possible to test the onboarding experience in Firefox for Android without using a simulator or wiping your existing data. We are currently waiting for engineers to update the default configuration to align with the onboarding experience in Firefox 148 and newer. We hope this update will land in time for the release of 148, and we will communicate the change via Pontoon as soon as that’s available.
In the meantime, please review the updated testing documentation to see how to trigger the onboarding flow. Note that some UI elements will display string identifiers instead of translations until the configuration is updated.
Firefox for iOS localization screenshots
We heard your feedback about the screenshot process for Firefox for iOS. Thanks to everyone who answered the survey at the end of last year.
Screenshots are now available as a gallery for each locale. There is no longer a need to download and decompress a local zip file. You can browse the current screenshots for your locale, and use the links at the top to review the full history or compare changes between runs (generated roughly every two weeks).
A reminder that links to testing environments and instructions are always available from the project header in Pontoon.
What’s new or coming up in web projects
Firefox.com
We’re planning some changes to how content is managed on firefox.com, and these updates will have an impact on our existing localization workflows. Once the details are finalized, we’ll share more information and notify you directly in Pontoon.
What’s new or coming up in Pontoon
Pontoon infrastructure update
Behind the scenes, Pontoon has recently completed a major migration from Heroku to Google Cloud Platform. While this change should be largely invisible to localizers in day-to-day use, it brings noticeable improvements in performance, reliability, and scalability, helping ensure a smoother experience as contributor activity continues to grow. Huge thanks go to our Cloud Engineering partners for supporting this effort over the past months and helping make this important milestone possible.
Friends of the Lion
Image by Elio Qoshi
Since relaunching the contributor spotlight blog series, we’ve published two more stories highlighting the people behind our localization work.
We featured Robb, a professional translator from Romania, whose love for words and her desire to help her mom keep up with modern technology has grown into a day-to-day commitment to making products and technology accessible in language that everyday people can understand.
We also spotlighted Andika from Indonesia, a long-time open source contributor who joined the localization community to ensure Firefox and other products feel natural and accessible for Indonesian-speaking users. His steady, long-term commitment to quality speaks volumes about the impact of thoughtful localization.
We’ll be continuing this series and are always looking for contributors to feature. You can help us find the next localizer to spotlight by nominating one of your fellow community members. We’d love to hear from you!
Know someone in your l10n community who’s been doing a great job and should appear here? Contact us and we’ll make sure they get a shout-out!
As is tradition, we’re wrapping up 2025 for Mozilla’s localization efforts and offering a sneak peek at what’s in store for 2026 (you can find last year’s blog post here).
Pontoon’s metrics in 2025 show a stable picture for both new sign-ups and monthly active users. While we always hope to see signs of strong growth, this flat trend is a positive achievement when viewed against the challenges surrounding community involvement in Open Source, even beyond Mozilla. Thank you to everyone actively participating on Pontoon, Matrix, and elsewhere for making Mozilla localization such an open and welcoming community.
30 projects and 469 locales (+100 compared to 2024) set up in Pontoon.
5,019 new user registrations
1,190 active users, submitting at least one translation, on average 233 users per month (+5% Year-over-Year)
551,378 submitted translations (+18% YoY)
472,195 approved translations (+22% YoY)
13,002 new strings to translate (-38% YoY).
The number of strings added has decreased significantly overall, but not for Firefox, where the number of new strings was 60% higher than in 2024 (check out the increase of Fluent strings alone). That is not surprising, given the amount of new features (selectable profiles, unified trust panel, backup) and the upcoming settings redesign.
As in 2024, the relentless growth in the number of locales is driven by Common Voice, which now has 422 locales enabled in Pontoon (+33%).
Before we move forward, thank you to all the volunteers who contributed their time, passion, and expertise to Mozilla’s localization over the last 12 months — or plan to do so in 2026. There is always space for new contributors!
Pontoon Development
A significant part of the work on Pontoon in 2025 isn’t immediately visible to users, but it lays the groundwork for improvements that will start showing up in 2026.
One of the biggest efforts was switching to a new data model to represent all strings across all supported formats. Pontoon currently needs to handle around ten different formats, as transparently as possible for localizers, and this change is a step to reduce complexity and technical debt. As a concrete outcome, we can now support proper pluralization in Android projects, and we landed the first string using this model in Firefox 146. This removes long-standing UX limitations (no more Bookmarks saved: %1$s instead of %1$s bookmarks saved) and allows languages to provide more natural-sounding translations.
In parallel, we continued investing in a unified localization library, moz-l10n, with the goal of having a centralized, well-maintained place to handle parsing and serialization across formats in both JavaScript and Python. This work is essential to keep Pontoon maintainable as we add support for new technologies and workflows.
Pontoon as a project remains very active. In 2025 alone, Pontoon saw more than 200 commits from over 20 contributors, not including work happening in external libraries such as moz-l10n.
Finally, we’ve been improving API support, another area that is largely invisible to end users. We moved away from GraphQL and migrated to Django REST, and we’re actively working toward feature parity with Transvision to better support automation and integrations.
Community
Our main achievement in 2025 was organizing a pilot in-person event in Berlin, reconnecting localizers from around Europe after a long hiatus. Fourteen volunteers from 11 locales spent a weekend together at the Mozilla Berlin office, sharing ideas, discussing challenges, and deepening relationships that had previously existed only online. For many attendees, this was the first time they met fellow contributors they had collaborated with for years, and the energy and motivation that came out of those days clearly showed the value of human connection in sustaining our global community.
This doesn’t mean we stopped exploring other ways to connect. For example, throughout the year we continued publishing Contributor Spotlights, showcasing the amazing work of individual volunteers from different parts of the world. These stories highlight not just what our contributors do, but who they are and why they make Mozilla’s localization work possible.
Internally, these spotlights have played an important role for advocating on behalf of the community. By bringing real voices and contributions to the forefront, we’ve helped reinforce the message that investing in people — not just tools — is essential to the long-term health of Mozilla’s localization ecosystem.
What’s coming in 2026
As we move into the new year, our focus will shift to exploring alternative deployment solutions. Our goal is to make Pontoon faster, more reliable, and better equipped to meet the needs of our users.
This excerpt comes from last year’s blog post, and while it took longer than expected, the good news is that we’re finally there. On January 6, we moved Pontoon to a new hosting platform. We expect this change to bring better reliability and performance, especially in response to peaks in bot traffic that have previously made Pontoon slow or unresponsive.
In parallel, we “silently” launched the Mozilla Language Portal, a unified hub that reflects Mozilla’s unique approach to localization while serving as a central resource for the global translator community. While we still plan to expand its content, the main infrastructure is now in place and publicly available, bringing together searchable translation memories, documentation, blog posts, and other resources to support knowledge-sharing and collaboration.
On the technology side, we plan to extend plural support to iOS projects and continue improving Pontoon’s translation memory support. These improvements aim to make it easier to reuse translations across projects and formats, for example by matching strings independently of placeholder syntax differences, and to translate Fluent strings with multiple values.
We also aim to explore improvements in our machine translation options, evaluating how large language models could help with quality assessment or serve as alternative providers for MT suggestions.
Last but not least, we plan to keep investing in our community. While we don’t know yet what that will look like in practice, keep an eye on this blog for updates.
If you have any thoughts or ideas about this plan, let us know on Mastodon or Matrix!
Thank you!
As we look toward 2026, we’re grateful for the people who make Mozilla’s localization possible. Through shared effort and collaboration, we’ll continue breaking down barriers and building a web that works for everyone. Thank you for being part of this journey.
My name is Andika. I’m from Indonesia, and I speak Indonesian, Javanese, and English. I’ve been contributing to Mozilla localization for a long time, long enough that I don’t clearly remember when I started. I mainly focus on Firefox and Thunderbird, but I also contribute to many other open source projects.
Exploring Padar Island where Komodo dragons can be spotted.
Contributing to Mozilla Localization
Q: Can you tell us a bit about your background and how you found localization?
A: I started my open source journey in the 1990s. Early on, I helped others through mailing lists by troubleshooting problems and answering questions. I also tried filing bugs and maintaining packages, but over time I felt those contributions didn’t always have a lasting impact.
Around 2005, I started translating open source software. Translation felt different — it felt like a contribution that could last longer than the technology itself. When I saw poor translation quality online, I felt I could do better, and that motivated me to get involved. Localization became the most meaningful way for me to give back.
Q: What does your contribution to Mozilla localization look like today?
A: I primarily work on Firefox and Thunderbird. Over the years, I’ve translated tens of thousands of strings although some of those strings no longer exist in the codebase and remain only in translation memory. I also contribute to many other open source organizations, but Mozilla remains one of my main areas of focus.
Even though I don’t always use the products I localize — my professional work involves backend work, a lot of remote troubleshooting and maintenance — I stay connected to the quality of the translations through community collaboration and shared practices.
Workflow, Habits, and Collaboration
Q: How do you approach your localization work and collaborate with others?
A: Most of my localization work happens incrementally. I often carry unfinished translation files on my laptop so I can continue working offline, especially when the internet connection isn’t reliable. When I have multiple modules to choose from, I usually start with the ones that have the fewest untranslated strings. Seeing a module reach full translation gives me a lot of satisfaction.
To avoid burnout, I set small, realistic goals, sometimes something as simple as translating 50 strings before switching to another task. I tend to use small pockets of free time throughout the day, like waiting at a public transportation station or an appointment, and those fragments add up.
Collaboration plays a big role in maintaining quality. Within the Indonesian localization community, we use Telegram to discuss difficult or new terms and work toward consensus. Terminology and style guides are maintained together; it’s not a one-person responsibility.
I’ve also worked on localization in other projects like GNOME, where we translate module by module, we review each other’s work, and then commit changes as a group. Compared to Pontoon’s string-by-string approach, this workflow offers more flexibility, especially when working offline.
Perspective Across Open Source and Beyond
Q: You contribute to many open source projects. How does Mozilla localization compare, and what would you like to see improved?
A: For Indonesian localization, Mozilla is the most organized team I’ve worked with and has the largest active team. Some projects may appear larger on paper, but active participation matters more than numbers, and that’s where Mozilla really stands out.
One improvement I’d like to see is better support for offline translation in Pontoon. Another area is shortcut conflict detection — translators often can’t easily see whether keyboard shortcuts conflict unless all menu items or dialog elements are rendered together. Automated checks or rendered views of translated dialogs would make that process much easier.
That said, one thing Pontoon does very well, and that other projects could learn from, is the improving quality of online and AI-assisted translation suggestions.
Speaking at Fosdem in February 2024 on “Long Term Effort to Keep Translations Up-To-Date”
Professional Life and a Personal Note
Q: What do you do professionally, and how does it connect with your localization work?
A: I work as an IT security consultant. I started using a PC in 1984, learning to program in BASIC, Pascal, FORTRAN, Assembly, and C. C is my most favorite language up to now. I also tried various OSes from CP/M, DOS, OS/2, VMS, Netware, Windows, SCO, Solaris, then fell in love with Linux. I have been using Debian since version 1.3. Later I changed my focus from programming into IT security. My job requires staying up to date with security concepts and terminology, which helps when translating security-related strings. At the same time, localization sometimes introduces me to features I might later use professionally. The two areas complement each other in unexpected ways.
As for something more personal: I hate horror movies, I love cats, and I’ve had the chance to witness the rise and fall of many technologies over the years. I also maintain a personal wiki to keep track of my open source work though I keep telling myself I need to migrate it to GitHub one day.
My profile in Pontoon is robbp, but I go by Robb. I’m based in Romania and have been contributing to Mozilla localization since 2018 — first between 2018 and 2020, and now again after a break. I work mainly on Firefox (desktop and mobile), Thunderbird, AMO, and SUMO. When I’m not volunteering for open-source projects, I work as a professional translator in Romanian, English, and Italian.
Getting Started
Q: How did you first get interested in localization? Do you remember how you got involved in Mozilla localization?
A: I’ve used Thunderbird for many years, and I never changed the welcome screen. I’d always see that invitation to contribute somehow.
Back in 2018, I was using freeware only — including Thunderbird — and I started feeling guilty that I wasn’t giving back. I tried donating, but online payments seemed shady back then, and I thought a small, one-time donation wouldn’t make a difference.
Around the same time, my mother kept asking questions like, “What is this trying to do on my phone? I think they’re asking me something, but it’s in English!” My generation learned English from TV, Cartoon Network, and software, but when the internet reached the older generation, I realized how big of a problem language barriers could be. I wasn’t even aware that there was such a big wave of localizing everything seen on the internet. I was used to having it all in English (operating system, browser, e-mail client, etc.).
After translating for my mom for a year, I thought, why not volunteer to localize, too? Mozilla products were the first choice — Thunderbird was “in my face” all day, all night, telling me to go and localize. I literally just clicked the button on Thunderbird’s welcome page — that’s where it all started.
I had also tried contributing to other open-source projects, but Mozilla’s Pontoon just felt more natural to me. The interface is very close to the CAT tools I am used to.
Your Localization Journey
Q: What do you do professionally? How does that experience influence your Mozilla work and motivate you to contribute to open-source localization?
A: I’ve been a professional translator since 2012. I work in English, Romanian, and Italian — so yes, I type all the time.
In Pontoon, I treat the work as any professional project. I check for quality, consistency, and tone — just like I would for a client.
I was never a writer. I love translating. That’s why I became a translator (professionally). And here… I actually got more feedback here than in my professional translation projects. I think that’s why I stayed for so long, that’s why I came back.
It is a change of scenery when I don’t localize professionally, a long way from the texts I usually deal with. This is where I unwind, where I translate for the joy of translation, where I find my translator freedom.
Q: At what moment did you realize that your work really mattered?
A: When my mom stopped asking me what buttons to click! Now she just uses her phone in Romanian. I can’t help but smile when I see that. It makes me think I’m a tiny little part of that confidence she has now.
Community & Collaboration
Q: Since your return, Romanian coverage has risen from below 70% to above 90%. You translate, review suggestions, and comment on other contributors’ work. What helps you stay consistent and motivated?
A: I set small goals — I like seeing the completion percentage climb. I celebrate every time I hit a milestone, even if it’s just with a cup of coffee.
I didn’t realize it was such a big deal until the localization team pointed it out. It’s hard to see the bigger picture when you work in isolation. But it’s the same motivation that got me started and brought me back — you just need to find what makes you hum.
Q: Do you conduct product testing after you localize the strings or do you test them by being an active user?
A: I’m an active user of both Firefox and Thunderbird — I use them daily and quite intensely. I also have Firefox Nightly installed in Romanian, and I like to explore it to see what’s changed and where. But I’ll admit, I’m not as thorough as I should be! Our locale manager gives me a heads-up about things to check which helps me stay on top of updates. I need to admit that the testing part is done by the team manager. He is actively monitoring everything that goes on in Pontoon and checks how strings in Pontoon land in the products and to the end users.
Q: How do you collaborate with other contributors and support new ones?
A: I’m more of an independent worker, but in Pontoon, I wanted to use the work that was already done by the “veterans” and see how I could fit in. We had email conversations over terms, their collaboration, their contributions, personal likes and dislikes etc. I think they actually did me a favor with the email conversations, given I am not active on any channels or social media and email was my only way of talking to them.
This year I started leaving comments in Pontoon — it’s such an easy way to communicate directly on specific strings. Given I was limited to emails until now, I think comments will help me reach out to other members of the team and start collaborating with them, too.
I keep in touch with the Romanian managers by email or Telegram. One of them helps me with technical terms, he helped get the Firefox project to 100% before the deadline. He contacts me with information on how to use options (I didn’t know about) in Pontoon and ideas on wording (after he tests and reviews strings). Collaboration doesn’t always mean meetings; sometimes it’s quiet cooperation over time.
Mentoring is a big word, but I’m willing for the willing. If someone reaches out, I’ll always try to help.
Q: Have you noticed improvements in Pontoon since 2020? How does it compare to professional tools you use, and what features do you wish it had?
A: It’s fast — and I love that.
There’s no clutter — and that’s a huge plus. Some of the “much-tooted” professional tools are overloaded with features and menus that slow you down instead of helping. Pontoon keeps things simple and focused.
I also appreciate being able to see translations in other languages. I often check the French and Italian versions, just to compare terms.
The comments section is another great feature — it makes collaboration quick and to the point, perfect for discussing terms or string-specific questions. Machine translation has also improved a lot across the board, and Pontoon is keeping pace.
As for things that could be better — I’d love to try the pre-translation feature, but I’ve noticed that some imported strings confirm the wrong suggestion out of several options. That’s when a good translation-memory cleanup becomes necessary. It would be helpful if experienced contributors could trim the TM, removing obsolete or outdated terms so new contributors won’t accidentally use them.
Pontoon sometimes lags when I move too quickly through strings — like when approving matches or applying term changes across projects. And, unlike professional CAT tools, it doesn’t automatically detect repeated strings or propagate translations for identical text. That’s a small but noticeable gap compared to professional tools.
Personal Reflections
Q: Professional translators often don’t engage in open-source projects because their work is paid elsewhere. What could attract more translators — especially women — to contribute?
A: It’s tricky. Translation is a profession, not a hobby, and people need to make a living.
But for me, working on open-source projects is something different — a way to learn new things, use different tools, and have a different mindset. Maybe if more translators saw it as a creative outlet instead of extra work, they’d give it a try.
Involvement in open source is a personal choice. First, one has to hear about it, understand it, and realize that the software they use for free is made by people — then decide they want to be part of that.
I don’t think it’s a women’s thing. Many come and many go. Maybe it’s just the thrill at the beginning. Some try, but maybe translation is not for them…
Q: What does contributing to Mozilla mean to you today?
A: It’s my way of giving back — and of helping people like my mom, who just want to understand new technology without fear or confusion. That thought makes me smile every time I open Firefox or Thunderbird.
Q: Any final words…
A: I look forward to more blogs featuring fellow contributors and learning and being inspired from their personal stories.
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
Welcome!
What’s new or coming up in Firefox desktop
Firefox Backup
Firefox backup is a new feature being introduced in Firefox 145, currently testable in Beta and Nightly behind a preference flag. See here for instructions on how to test this feature.
This feature allows users to save a backup of their Firefox data to their local device at regular intervals, and later use that backup to restore their browser data or migrate their browser to a new device. One of the use cases is for current Windows 10 users who may be migrating to a new Windows 11 device. The user can save their Firefox backup to OneDrive, and later after setting up their new device can then install Firefox and restore their browsing data from the backup saved in OneDrive.
This is an alternative to using the sync functionality in combination with a Mozilla account.
Settings Redesign
Coming up in future releases, the current settings menu is being re-organized and re-designed to be more user friendly and easier to understand. New strings will be rolling out with relative frequency, but they can’t be viewed or tested in Beta or Nightly yet. If you encounter anything where you need additional context, please feel free to use the request context button in Pontoon or drop into our localization matrix channel where you can get the latest updates and engage with your fellow localizers from around the world.
What’s new or coming up in mobile
Here’s what’s been going on in Firefox for Android land lately: you may have noticed strings landing for the Toolbar refresh, the tab tray layout, as well as for a homepage revamp. All of this is work is ongoing, so expect to see more strings landing soon!
On the Firefox for iOS side, there have been improvements to Search along with a revamp of the menu and tab tray. Ongoing work continues on the Translations feature integration, the homepage revamp, and the toolbar refresh.
More updates coming soon — stay tuned!
What’s new or coming up in web projects
AMO and AMO Frontend
The team has been working on identifying and removing obsolete strings to minimize unnecessary translation effort especially the locales that are still catching on. Recently they removed an additional 160 or so strings.
To remain in production, a locale must have both projects at or above 80% completion. If only one project meets the threshold, neither will be enabled. This policy helps prevent users from unintentionally switching between their preferred language and English. Please review your locale to confirm both projects are localized and in good standing.
If a locale already in production falls below the threshold, the team will be notified. Each month, they will review the status of all locales and manually add or remove them from production as needed.
Mozilla accounts
The Mozilla accounts team has been working on the ability to customize surfaces for the various projects that rely on Mozilla accounts for account management such as sync, Mozilla VPN, and others. This customization applies only to a predetermined set of pages (such as sign-in, authentication, etc.) and emails (sign-up confirmation, sign-in verification code, etc.) and is managed through a content management system. This CMS process bypasses the typical build process and as a result changes are shown in production within a very short time-frame (within minutes). Each customization requires an instance of a string, even if that value hasn’t changed, so this can result in a large number of identical strings being created.
This project will be managed in a new “Mozilla accounts CMS” project within Pontoon instead of the main “Mozilla accounts” project. We are doing this for a couple reasons:
To reduce or eliminate the need to translate duplicate strings: In most cases it’s best to have different strings to allow for translation adjustments depending on context, however due to the nature of this project, identical strings for the same page element (e.g. “button”) will use a single translation. For example, all buttons with the text “Sign in” will only require a single translation. This has reduced the number of strings requiring translation by over 50% already, and will reduce the number of additional strings in the future.
To enable pretranslation:Important note – this only applies to locales that have opted-in to the pretranslation feature. Due to the CMS string process skipping the normal build cycle and being exposed to production near instantaneously, there’s a high likelihood that untranslated strings may be shown in English before teams have the chance to translate. If a locale has opted in for pretranslation, then the “Mozilla accounts CMS” project will have pretranslation enabled by default and show pretranslated strings until the team has a chance to review and update strings. If your locale has decided not to use the pretranslation feature, then nothing will change and translated strings will be displayed once your team has them translated and approved in Pontoon.
Newly published localizer facing documentation
We’ve recently updated our testing instructions for Firefox for Android and for Firefox for iOS! If you spot anything that could be improved, please file an issue — we’d love your feedback.
Friends of the Lion
Image by Elio Qoshi
We’ve started a new blog series spotlighting amazing contributors from Mozilla’s localization community. The first one features Selim of the Turkish community.
A second localizer spotlight was published! This time, meet Bogo, a long-time contributor to Bulgarian projects.
Want to learn more from your fellow contributors? Who would you like to be featured? You are invited to nominate the next candidate!
Know someone in your l10n community who’s been doing a great job and should appear here? Contact us and we’ll make sure they get a shout-out!
Questions? Want to get involved?
If you want to get involved, or have any question about l10n, reach out to:
My name is Bogomil but people call me Bogo, and I am a translator for the Bulgarian locale. I think I got involved with the Mozilla project back in 2005 when I wrote a small search add-on/script. I became more active around 2008-2009 and with just a few gaps until this day.
I am European. I was born in Bulgaria, but I have been living for a long time in the Czech Republic. Bulgarian is my main language, but sometimes I contribute to localization projects in Turkish, Romanian, Macedonian and Czech.
Q&A
Q: What inspired you to join the Mozilla localization community?
A: As I mentioned here I decided to start localizing software because I knew some people had trouble using it in other languages. I believe everyone deserves the right to use software in a language they understand which helps them to get the maximum value out of it. As for Mozilla in particular I believe in the mission and this is the most efficient way for me to contribute.
Q: How do you solve challenges like bugs or workflow hiccups, especially when collaborating virtually?
A: Since we are a small team for the Bulgarian localizations we are almost always in sync on how to translate the strings. We are following some basic rules, such as using a common dictionary and instructions on how to localize software in Bulgarian (shared across multiple FOSS projects), set 15+ years ago and that are still relevant. When we have a conflict, I usually count on the team managers to share their wisdom, because they have a bit more knowledge than the rest of us.
Q: Which projects or new product features were you most excited about this year, and why?
A: In the last year I contributed mainly to the Thunderbird project. The items that are most exciting to me are:
That finally we decided to remove the word “Junk” and replace it with “Spam”, I think this is self-explanatory 🙂
The new Account Hub which improves significantly the consumer’s experience and their onboarding into the beautiful world of the free email. Free as in Freedom.
I am also excited about all the things in the roadmap to come.
Q: What tips, tools, or habits help you succeed as a localizer?
A: If you look at my Pontoon profile, you will see that for the last 2 months I contributed every day. I find this habit very useful for me, because it keeps me focused on my goal for consistently improving the localized experience.
Another item is that I like to provide a better experience to the mobile users. I often test and fix labels in Thunderbird for Android which, even translated correctly, are too long for a mobile phone UI.
And lastly, I love to engage with the community and ask them for help when we finish a section or a product. Last year we asked the Bulgarian community to help us validate a localization available in the beta version and we got some very helpful feedback.
Something fun
Q: Could you share a few fun or unexpected facts about yourself that people might not know?
I ran for the European Parliament in 2009 with the intention to fight for our digital rights.
I was on almost every media in the world in 2012 when I bought the data of millions of users for $5! This is the Forbes article.
I am a heavy metal fan and you can find me in underground clubs, enjoying bands you have never heard of.
Apart from technology I am an artist – I produced and performed my own theater play and shot a movie in Prague.
I realized my dream to have an opening talk at FOSDEM. I was opening the Sunday session… but still!
My name is Selim and I’m the Turkish localization manager. I’m from İstanbul, Türkiye. I’ve been contributing to Mozilla since 2010.
Your Contributions
Selim (first left) with fellow Turkish Mozillians Onur, Didem and Serkan (Mozilla Summit Brussels)
Q: Over the years, do you remember how many projects you’ve been involved in (including ones that may no longer exist)?
A: It’s been so many! I began with Firefox 15 years ago, but I think I’ve been involved in around 30 projects over the years. We currently have 23 projects active in Pontoon, and I’ve been involved in every single one of them to some degree.
Q: Roughly how many Mozilla events have you joined — whether localization meetups, company-wide gatherings, MozFest, or others?
A: I’ve attended six of them. My first one was the Mozilla Balkans Meetup 2011 in Sofia. Then I had the chance to meet fellow Mozillians in Zagreb, Brussels, Berlin, Paris, and my hometown İstanbul. They were all great experiences, both enlightening and rewarding.
Q: Looking back, are there any contributions or milestones you feel especially proud of?
A: When I first began contributing, my intention was to complete a few missing translations I had noticed in Firefox. However, I quickly realized that the project was huge and there was much more to it than met the eye. Its Turkish localization was around 85% complete at that time, but the community lacked the resources to push it forward. I took it as my duty to reach 100% first, and then spellcheck and fix all existing translations. It took me a few months to get there, but Firefox has clearly had the best Turkish localization among all browsers ever since.
Your Background
Q: Does your professional background support or connect with your work in localization?
A: I currently work as a freelance editor and translator, translating and editing print magazines (mostly tech, popular science, and general knowledge titles), and localizing software and websites.
And the event that kickstarted my career in publishing and professional translation was volunteering for localization. (No, not Firefox. It didn’t even exist yet!) Back in high school, I began localizing an open-source CMS called PHP-Nuke to be used on my school’s website. PHP-Nuke became very popular in a short amount of time, and a computer magazine editor approached me to build the magazine’s website using open-source tools, including PHP-Nuke. I’ve been an avid reader of those magazines since my childhood but never imagined that one day I’d be working for Türkiye’s best-selling computer magazine!
In time, I began translating and writing articles for the magazine as a freelancer and joined the editorial staff after graduating from university.
I’ve written hundreds of software and website reviews and kept noticing that some of them were high-quality products that needed better localization. Now, with a better understanding of how things work and with some technical background, I began contributing to more and more open-source projects in my free time, and Firefox was one of them.
I was lucky that the previous Turkish contributors did a great job “localizing” Firefox, not just translating it. I learned a great deal from them, and it had a huge impact on my later professional work.
I was also approached and/or approved by several clients who had seen my volunteer localization work.
So, in a way, my professional background does support my work in localization — and vice versa.
Q: In what ways has being part of Mozilla’s localization community influenced you — whether in problem-solving, leadership, or collaborating across cultures?
A: Once I started contributing, I quickly realized that Mozilla had something none of the other projects I had contributed to previously had: a community that I felt part of. These people loved the internet, and they were having fun localizing stuff, just like me.
The localization community helped me improve myself both professionally and personally in a lot of ways: I learned how to collaborate better with a team of volunteers from different backgrounds, how to use different translation tools, how to properly report bugs, how to deal with different time zones, and how to get out of my comfort zone and talk to people from abroad both in virtual and face-to-face events.
Your Community
Q: As a long-time contributor, what motivates you to continue after all these years?
A: First and foremost, I believe in Mozilla’s mission wholeheartedly. But there’s a practical motivation too: Turkish is spoken by tens of millions of people, so the potential impact of localization is huge. Ensuring my fellow nationals have access to high-quality, localized open-source software is a driving force. And I’m still having fun doing it!
Q: Many communities struggle with onboarding or retaining contributors, especially after COVID limited in-person events. What are the challenges you face as a manager and how do you address them? And how do you engage with active contributors today? Do you have a process or approach for welcoming newcomers?
A: The Turkish community had its fair share of struggles with onboarding and retaining contributors, but it never became a huge challenge because of an advantage we had: The first iteration of the community started very early. Firefox 1.0 was already available in Turkish, and they maintained a good localization percentage for most Mozilla products, even if not 100%. So when I joined, there were things to do but not a single project that needed to be started from scratch. They were maintainable by one or two enthusiastic localizers. And when I took on the manager role, I always tried to keep it that way. I did approve a number of new projects, but not before ensuring that we had the resources to always keep them at least 90% complete.
But that creates a dilemma: New Turkish contributors usually face strings that are harder to grasp without context or are more difficult to translate, because the easier and more visible strings have already been translated. I guess that makes newcomers frustrated and they leave after translating a few strings. In fact, over the past 10 years, we’ve had only one contributor (Grk) who has translated more than 10,000 strings (apart from myself), and two contributors (Ali and Osman) with more than 1,000 strings. I’d like to thank them once again for their awesome contributions.
The Turkish community has always been very small: just a few people contributing at a time, and that has worked for us. So I’m not anxiously trying to onboard or retain contributors, but if I see an enthusiastic newcomer, I try to guide them by commenting on their translations or sending a welcome email to let them know how things work.
Something Fun Q: Could you share a few fun or unexpected facts about yourself that people might not know?
A: Certainly:
I’m a metalhead, and the first thing I ever translated as a hobby was the lyrics of a Sentenced song. I’ve been translating song lyrics ever since, and I have a blog where I publish them.
I built my first website when I was 13, by manually typing HTML in Windows Notepad. That’s when I discovered the internet’s endless possibilities and fell in love with it.
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
What’s new or coming up in Firefox desktop
Where’s Firefox Going Next?
Before getting into all the new features that recently landed in Nightly, we’re trying something new and would love your help. Check out this thread over on Mozilla Connect where you can help Firefox’s product managers plan their upcoming AMA (Ask Me Anything) by letting them know what you’ve always wanted to ask the Firefox team and which topics should be covered during the AMA.
Trust Panel
Available to translate and test in Nightly, the trust panel is a new feature designed to communicate to users what Firefox is doing to protect their privacy in friendly and easy to understand language. To check the feature out and review your translations, make sure to update your Nightly to the latest version (143) then navigate to “about:config” by typing it into your URL bar, click past the warning, then search browser.urlbar.trustPanel.featureGate and toggle the value to true.
Navigate to a website and the icon will appear on the side of your URL bar.
Clicking on it will show you the trust panel with a friendly Firefox letting you know you’re protected!
Profile Icons
Also recently landed was a large number of strings related to icons users can set as part of the recently added profiles feature. While we tried to make the comments as helpful as possible, there’s no substitute for seeing the image in context. You can check the icons out within Nightly yourself by editing or creating a new profile by clicking the Account button on your toolbar and selecting the Profiles menu. Or, you can refer to the following image with a screenshot and the associated name used in the string IDs.
Text Fragments
You can now test the text fragments creation UI (these strings were added a few months back, but they have just been activated in Firefox Nightly). This feature allows you to share/reference a link anchor to any text snippet in a page. See the team’s post about this feature here.
What’s new or coming up in mobile
The menu settings on Firefox for Android and iOS are being redesigned, which requires updates to some strings. Stay tuned as more are coming in!
What’s new or coming up in web projects
Firefox.com
The new Firefox.com site officially launched earlier this month following a soft launch period, which allowed time to identify and resolve any initial issues. Thank you to everyone who reported bugs during that time. Most of the content on the new site was copied from Mozilla.org. However, the team plans to remove duplicated pages over the next few months except for a few that will remain on both sites, such as the Thank You page. More substantial updates are planned for later this year and beyond.
What’s new or coming up in Pontoon
Unified plurals UI
We’ve updated how plural gettext (.po) messages are handled in Pontoon. Specifically, they now use the same UI we’ve already been using for Fluent strings.
We’d really appreciate your feedback! To explore the new plural editor, try searching for strings that include .match, which commonly contain plural forms. We’re especially interested in whether the new experience feels intuitive and “right”, and — most importantly — if you manage to break it.
New REST API Now Available
We’re excited to announce that Pontoon now offers a new REST API, built with Django REST Framework! This API is designed to provide a more reliable and consistent way to interact with Pontoon programmatically, and it’s already available for use.
You can explore the available endpoints and usage examples in the API README.
GraphQL API Scheduled for Deprecation
As part of this transition, we’ll be deprecating the Pontoon GraphQL API on November 5th, 2025. If you’re currently using the GraphQL API, we strongly encourage you to begin migrating to the new REST API, which will become the only supported interface going forward.
If you have any questions during the transition or run into issues, please don’t hesitate to open a discussion or file an issue. We’re here to help!
Many have commented on the Summit, some wildly enthusiastic and others more critical. On the enthusiastic side, I heard excitement about the scope of local entrepreneurs and practitioners, the explicit calls for the Africa region to take care of itself and not wait for others to “assist” to a sense of the Summit as a foundation for important future action. On the critical side I heard concerns that the amount of Western funding influencing direction, and concerns that building infrastructure like data centers gets attention relative to building other parts of the AI “stack.” I’m going to leave a evaluation of the full Summit to those with far better context and understanding of the region. For my part, I’ll focus on on the side events.
I was very heartened to see the diversity of side events that occurred during and around the Summit. I’ve found these side events can make or break an event, quite separate from the official content. The scope and diversity of side events gives a picture of how many groups feel the event touches on important topics and brings together interesting people. I attended a couple of side events myself, and learned of multiple other side events as I talked to people during the Summit. One such event was all day, bringing together policy professionals and ministerial staff. Another brought together AI practitioners from around the Continent who rarely if ever get together for in person community building. This struck me as very powerful, perhaps because I have such vivid memories of the first time the Firefox community got together. This was after we shipped Firefox 1.0, so after we had worked remotely for years to build a browser. That era was before video calls, and so we often knew each other through written materials only. Getting together physically made a dramatic mental difference and made us much more productive for a good long while. The organizer of this gathering at the Summit was practically buzzing with excitement at the chance to finally bring this community together.
I did participate in an evening panel for a research colloquium where the working energy was so loud it almost overpowered the microphones of the panelists. I also participated in a quiet breakfast side event that brought together practitioners and policy wonks for a reasonably frank discussion on what’s working and what challenges need attention. On the official side, I was part of a panel on Innovating for a Healthier Future. My main comments were focused on the themes of “open must win” and the “ethos of open.” (These are in minutes 33 to 38.)
I see the inclusion of side events as a big success. In particular, having AI practitioners, entrepreneurs, professors mixing with each other as well as policy makers and government officials. Building new things is what drives change. Policy can help or harm this effort dramatically.
A couple of months ago I started posting about how I want to build a better world through technology and how I’ll be doing that outside of Mozilla going forward. The original post has many references to “open” and “open source.” It’s easy to think that we all understand open source and we just need to apply it to new settings. I feel differently: we need to shape our collective understanding of the ethos of open source.
Open source has become mainstream as a part of the software development process. We can rightly say that the open source movement “won.” However, this isn’t enough for the future.
The open source movement was about more than convenience and avoiding payment. For many of us, open source was both a tool and an end in itself. Open source software allows people to participate in creating the software that has such great impact on our lives. The “right to fork” allows participants to try to correct wrongs in the system; it provides a mechanism for alternatives to emerge. This isn’t a perfect system of course, and we’ve seen how businesses can wrap open source and the right to fork with other systems that diminish the impact of this right. So the past is not “The Perfect Era” that we should aim to replicate. The history of open source gives us valuable learning into what works and what doesn’t so we can iterate towards what we need in this era.
The practical utility of open source software has become mainstream. The time is ripe to reinforce the deeper ethos of participation, opportunity, security and choice that drove the open source movement.
I’m looking for a good conversation about these topics. If you know of a venue where such conversations are happening in a thoughtful, respectful way please do let me know.
I’m on my way to the Global AI Summit on Africa in Kigali on April 3 and 4, thanks to an invitation from the Ministry organizing the event. I’ll be speaking, but mostly listening and learning and hopefully connecting with people who are drawn to approaches that are open and creative. If you know someone at this event I should meet, please do let me know.
I’m scheduled to be the main guest at the Fireside Chat on April 1. I’ll also be participating in the panel “Innovating for a Healthier Future.” This panel topic combines open source and health with new AI developments. I’ve been working with OpenMRS (as a board member) on open source electronic medical records for better outcomes for some years. I’m eager to dive into the impacts of AI on this work with the broad set of experts at the Summit.
After the Summit, I’ll spend a few days in Nairobi. I’ll say more about the Summit shortly.
I’ve been thinking a lot about how we need to shape our collective understanding of the ethos of open source, and how to use business as a tool to promote mission-based work.
Here are a few areas where ideas are percolating and I expect to write more soon:
What does the evolution of open source from “radical” niche developers into the consumer mainstream teach us?
It’s clear that “open must win” in the AI realm so that public benefit is magnified. This is a huge topic, from definitions to community building to integrating open projects into robust products.
How does one use business as a tool to promote a mission, or to support a mission based organization?
This is a space I’ve been living in for 25 years and is more important than ever. I’ve lived through the changes different styles of leadership and different priorities can make. I’ve experienced how the logic of business is very strong, while unconventional thinking is — well — unconventional, and harder to institutionalize. I’ve experienced, and in some cases led, some big wins here and some big misses as well. I have a lot of ideas about how to do this in the current environment. I’m not alone in this, there’s a growing community of people thinking about these areas with whom I’m eager to connect.
Time of Disruption
So much is changing now. It’s a time of disruption at the individual, national and global levels. This means new ways of creating and organizing activities and developing new institutions is necessary. We need the positive forces of building and doing to be a part of the coming new order.
These topics are just a starting point. I want to get involved with people doing related activities, building, supporting, funding new technology and new systems. If you are deep in one of these areas, please do ping me.
I am driven to build a better world through how we build technology that promotes opportunity, agency, and public benefit. I have pursued this mission through Mozilla for more than 25 years – first as a Netscape employee, then as a volunteer leader of Mozilla, then as the co-founder and leader of Mozilla Foundation and Mozilla Corporation. I am still driven by this mission, which is as important as ever. I will of course always be the co-founder of Mozilla but going forward I will pursue this mission outside of Mozilla.
I’ll share more details on my next steps soon. Today I want to focus on how I’ll be approaching this mission outside of Mozilla.
Mozilla’s upcoming era will have a focus on managing its portfolio of organizations, and the work described in Mozilla’s recent blog post. My personal approach going forward will be quite different. I’m aiming for new incarnations of the heart and spirit that built the open source movement and created Mozilla.
As Mozilla has grown I’ve experienced the opportunities and challenges in operating a $1 billion+ organization that is also a global technology platform and the flag-bearer for so many aspirations for a better internet. It’s a wildly valuable experience, and quite rare in the “open must win” world. I increasingly feel the pull to connect these experiences to new grassroots entrepreneurs, builders and movements. If I had had access to this experience when we were starting Mozilla it would have been a huge asset.
I have another creative burst or two in me waiting for the right opportunity. I know that the ethos of “open” and the principles of the Mozilla Manifesto are each increasingly important in the world today. There are only a handful of people who have lived through the explosion of “open” into the mainstream, who have developed that into a successful consumer product based on values, and then led an organization and a community through global scale and impact. I am one of this very small group and I feel compelled to use this experience to support others working in related fields. I want to find other people who are building things because those things need to exist in the world first, and then figure out how to generate revenue and build sustainability. I’m looking to immerse myself in opportunities that generate true creativity and breathe life into something new.
I’m learning exciting things these days. It has become even clearer to me that both “open must win” and the passion that has driven my leadership of Mozilla remain a clarion call for me. I will continue to explore my contribution to these areas in the next phase of my work through a broad range of contexts. In addition, the ability to represent this perspective in the public discourse is an honor and a responsibility to which I remain committed.
By “building a better world through how we build technology” I mean:
Offering more opportunities to more people to participate in creating our world, independent of educational pedigree or job title.
Internalizing “open” and open source as both a means and an end in itself.
Using open source to offer a “trust but verify” approach to how our technology operates and how it impacts individual sovereignty and our society.
Using private initiative to build public good – building business as a tool for public benefit.
Deepening transparency and individual agency.
Creating technology through combined efforts and shared assets.
I think of this approach as advocacy through building technology, using an “architecture of participation.” Many of us think of it as the ethos of open source. The possibility of this approach is hard to internalize until one experiences this directly, and is wildly powerful once one has. It’s the power that made Mozilla successful. Personally, it’s the power that kept me going whenever the work was really hard. And it’s the power that drives me to want to continue building and working on the “open must win” ethos.
The inspiration and impact of Mozilla are beyond anything I could have imagined. Words cannot express my gratitude to every one of you who chooses Mozilla, supports Mozilla, volunteers, chooses open, works for the public benefit, and resonates to the ideals we captured in the Mozilla Manifesto. I’m humbled by each of you who has chosen me as your leader, allows me to represent you in the world, and gives me the support to bring the best of our shared work into the world. This is a level of trust and commitment that I am proud and honored to have earned. It’s my deep hope to build on that in ways that reflect the core principles that have brought us together.
You can reach me on Mastodon or BlueSky or Linkedin or here at hello@mitchellbaker.net where I’ll provide updates. Mozilla email should forward to me for the next few months. Those of you who know me well enough to have my personal contact info, or to know someone who does, please do feel free to contact me. I may be slow to respond, but I’m driven by community and inspired by Mozillians, so don’t be shy!
I’ll share more details on my next steps soon. Today I want to focus on how I’ll be approaching this mission outside of Mozilla.
Mozilla’s upcoming era will have a focus on managing its portfolio of organizations, and the work described in Mozilla’s recent blog post. My personal approach going forward will be quite different. I’m aiming for new incarnations of the heart and spirit that built the open source movement and created Mozilla.
As Mozilla has grown I’ve experienced the opportunities and challenges in operating a $1 billion+ organization that is also a global technology platform and the flag-bearer for so many aspirations for a better internet. It’s a wildly valuable experience, and quite rare in the “open must win” world. I increasingly feel the pull to connect these experiences to new grassroots entrepreneurs, builders and movements. If I had had access to this experience when we were starting Mozilla it would have been a huge asset.
I have another creative burst or two in me waiting for the right opportunity. I know that the ethos of “open” and the principles of the Mozilla Manifesto are each increasingly important in the world today. There are only a handful of people who have lived through the explosion of “open” into the mainstream, who have developed that into a successful consumer product based on values, and then led an organization and a community through global scale and impact. I am one of this very small group and I feel compelled to use this experience to support others working in related fields. I want to find other people who are building things because those things need to exist in the world first, and then figure out how to generate revenue and build sustainability. I’m looking to immerse myself in opportunities that generate true creativity and breathe life into something new.
I’m learning exciting things these days. It has become even clearer to me that both “open must win” and the passion that has driven my leadership of Mozilla remain a clarion call for me. I will continue to explore my contribution to these areas in the next phase of my work through a broad range of contexts. In addition, the ability to represent this perspective in the public discourse is an honor and a responsibility to which I remain committed.
By “building a better world through how we build technology” I mean:
Offering more opportunities to more people to participate in creating our world, independent of educational pedigree or job title.
Internalizing “open” and open source as both a means and an end in itself.
Using open source to offer a “trust but verify” approach to how our technology operates and how it impacts individual sovereignty and our society.
Using private initiative to build public good – building business as a tool for public benefit.
Deepening transparency and individual agency.
Creating technology through combined efforts and shared assets.
I think of this approach as advocacy through building technology, using an “architecture of participation.” Many of us think of it as the ethos of open source. The possibility of this approach is hard to internalize until one experiences this directly, and is wildly powerful once one has. It’s the power that made Mozilla successful. Personally, it’s the power that kept me going whenever the work was really hard. And it’s the power that drives me to want to continue building and working on the “open must win” ethos.
The inspiration and impact of Mozilla are beyond anything I could have imagined. Words cannot express my gratitude to every one of you who chooses Mozilla, supports Mozilla, volunteers, chooses open, works for the public benefit, and resonates to the ideals we captured in the Mozilla Manifesto. I’m humbled by each of you who has chosen me as your leader, allows me to represent you in the world, and gives me the support to bring the best of our shared work into the world. This is a level of trust and commitment that I am proud and honored to have earned. It’s my deep hope to build on that in ways that reflect the core principles that have brought us together.
You can reach me on Mastodon or BlueSky or Linkedin or here at hello@mitchellbaker.net where I’ll provide updates. Mozilla email should forward to me for the next few months. Those of you who know me well enough to have my personal contact info, or to know someone who does, please do feel free to contact me. I may be slow to respond, but I’m driven by community and inspired by Mozillians, so don’t be shy!
March 31, or “three thirty-one,” is something of a talisman in the Mozilla community. It’s the date that, back in 1998, Mozilla first came into being — the date that we open-sourced the Netscape code for the world to use.
This year, “three thirty-one” is especially meaningful: It’s Mozilla’s 25 year anniversary.
A lot has changed since 1998. Mozilla is no longer just a bold idea. We’re a family of organizations — a nonprofit, a public benefit-corporation, and others — that builds products, fuels movements, and invests in responsible tech.
And we’re no longer a small group of engineers in Netscape’s Mountain View office. We’re technologists, researchers, and activists located around the globe — not to mention tens of thousands of volunteers.
But if a Mozillian from 1998 stepped into a Mozilla office (or joined a Mozilla video call) in 2023, I think they’d quickly feel something recognizable. A familiar spirit, and a familiar set of values.
When Mozilla open-sourced our browser code 25 years ago, the reason was the public interest: We wanted to spark more innovation, more competition, and more choice online. Technology in the public interest has been our manifesto ever since — whether releasing Firefox 1.0 in 2004, or launching Mozilla.ai earlier this year.
Right now, technology in the public interest seems more important than ever before. The internet today is deeply entwined with our personal lives, our professional lives, and society at large. The internet today is also flawed. Centralized control reduces choice and competition. A focus on “engagement” magnifies outrage, and bad actors are thriving.
Right now — and over the next 25 years — Mozilla can do something about this.
Mozilla’s mission and principles are evergreen, and we will continue to evolve to meet the needs and challenges of the modern internet. How people use the internet will change over time, but the need for innovative products that give individuals agency and choice on the internet is a constant. Firefox has evolved from a faithful and efficient render of web pages on PCs to a cross-platform agent that acts on behalf of the individual, protecting them from bad actors and surveillance capitalists as they navigate the web. Mozilla has introduced new products, such as Firefox Relay and Mozilla VPN, to keep people’s identity protected and activity private as they use the internet. Mozilla is contributing to healthy public discourse, with Pocket enabling discovery of amazing content and the mozilla.social Mastodon instance supporting decentralized, community-driven social media.
We’re constantly exploring ways to apply new technologies so that people feel the benefits in their everyday lives, as well as inspire others to responsibly innovate on behalf of humanity. As AI emerges as a core building block for the future of computing, we’ll turn our attention in that direction and ask: How can we make products and technologies like machine learning work in the public interest? We’ve already started this work via Mozilla.ai, a new Mozilla organization focusing on a trustworthy, independent, and open-source AI ecosystem. And via the Responsible AI Challenge, where we’re convening (and funding) bright people and ambitious projects building trustworthy AI.
And we will continue to champion public policy that keeps the internet healthy. There is proposed legislation around the world that seeks to maintain the internet in the public interest: the Platform Accountability and Transparency Act (PATA) in the U.S., the Digital Services Act (DSA) in the EU. Mozilla has helped shape these laws, and we will continue to follow along closely with their implementation and enforcement.
On this “three thirty-one,” I’m realistic about the challenges facing the internet. But I’m also optimistic about Mozilla’s potential to address them. And I’m looking forward to another 25 years of not just product, but also advocacy, philanthropy, and policy in service of a better internet.
As Mozilla reaches its 25th anniversary this year, we’re working hard to set up our ‘next chapter’ — thinking bigger and being bolder about how we can shape the coming era of the internet. We’re working to expand our product offerings, creating multiple options for consumers, audiences and business models. We’re growing our philanthropic and advocacy work that promotes trustworthy AI. And, we’re creating two new Mozilla companies, Mozilla.ai: to develop a trustworthy open source AI stack and Mozilla Ventures: to invest in responsible tech companies. Across all of this, we’ve been actively recruiting new leaders who can help us build Mozilla for this next era.
With all of this in mind, we are seeking three new members for the Mozilla Foundation Board of Directors. These Board members will help grow the scope and impact of the Mozilla Project overall, working closely with the Boards of the Mozilla Corporation, Mozilla.ai and Mozilla Ventures. At least one of the new Board members will play a central role in guiding the work of the Foundation’s charitable programs, which focuses on movement building and trustworthy AI.
What is the role of a Mozilla board member?
I’ve written in the past about the role of the Board of Directors at Mozilla.
At Mozilla, our board members join more than just a board, they join the greater team and the whole movement for internet health. We invite our board members to build relationships with management, employees and volunteers. The conventional thinking is that these types of relationships make it hard for executives to do their jobs. We feel differently. We work openly and transparently, and want Board members to be part of the team and part of the community.
Mozilla is a rare organization. We’re activists for a better internet, one where individuals and societies benefit more from the effects of technology, and where competition brings consumers choices beyond a small handful of integrated technology giants.
We’re activists who champion change by building alternatives. We build products and compete in the consumer marketplace. We combine this with advocacy, policy, and philanthropic programs connecting to others to create change. This combination is rare.
It’s important that our Board members understand all this, including why we build consumer products and why we have a portfolio of organizations playing different roles. It is equally important that the Boards of our commercial subsidiaries understand why we run charitable programs within Mozilla Foundation that complement the work we do to develop products and invest in responsible tech companies.
What are we looking for?
At the highest level, we are seeking people who can help our global organization grow and succeed — and who ensure that we advance the work of the Mozilla Manifesto over the long run. Here is the full job description: https://mzl.la/MofoBoardJD2023
There are a variety of qualities that we seek in all Board members, including a cultural sense of Mozilla and a commitment to an open, transparent, community driven approach. We are also focused on ensuring the diversity of the Board, and fostering global perspectives.
As we recruit, we typically look to add specific skills or domain expertise to the Board. Current examples of areas where we’d like to add expertise include:
Mission-based business — experience creating, running or overseeing organizations that combine public benefit and commercial activities towards a mission.
Global, public interest advocacy – experience leading successful, large-scale public interest advocacy organizations with online mobilization and shaping public discourse on key issues at the core.
Effective ‘portfolio’ organizations – experience running or overseeing organizations that include a number of divisions, companies or non-profits under one umbrella, with an eye to helping the portfolio add up to more than the sum of its parts.
Finding the right people who match these criteria and who have the skills we need takes time. Board candidates will meet the existing board members, members of the management team, individual contributors and volunteers. We see this as a good way to get to know how someone thinks and works within the framework of the Mozilla mission. It also helps us feel comfortable including someone at this senior level of stewardship.
We want your suggestions
We are hoping to add three new members to the Mozilla Foundation Board of Directors over the next 18 months. If you have candidates that you believe would be good board members, send them to msurman@mozillafoundation.org. We will use real discretion with the names you send us.
Mozilla is a global community that is building an open and healthy internet. We do so by building products that improve internet life, giving people more privacy, security and control over the experiences they have online. We are also helping to grow the movement of people and organizations around the world committed to making the digital world healthier.
As we grow our ambitions for this work, we are seeking new members for the Mozilla Foundation Board of Directors. The Foundation’s programs focus on the movement building side of our work and complement the products and technology developed by Mozilla Corporation.
What is the role of a Mozilla board member?
I’ve written in the past about the role of the Board of Directors at Mozilla.
At Mozilla, our board members join more than just a board, they join the greater team and the whole movement for internet health. We invite our board members to build relationships with management, employees and volunteers. The conventional thinking is that these types of relationships make it hard for the Executive Director to do his or her job. I wrote in my previous post that “We feel differently”. This is still true today. We have open flows of information in multiple channels. Part of building the world we want is to have built transparency and shared understandings.
It’s worth noting that Mozilla is an unusual organization. We’re a technology powerhouse with broad internet openness and empowerment at its core. We feel like a product organization to those from the nonprofit world; we feel like a non-profit organization to those from the technology industry.
It’s important that our board members understand the full breadth of Mozilla’s mission. It’s important that Mozilla Foundation Board members understand why we build consumer products, why it happens in the subsidiary and why they cannot micro-manage this work. It is equally important that Mozilla Corporation Board members understand why we engage in the open internet activities of the Mozilla Foundation and why we seek to develop complementary programs and shared goals.
What are we looking for?
Last time we opened our call for board members, we created a visual role description. Below is an updated version reflecting the current needs for our Mozilla Foundation Board.
Here is a short explanation of how to read this visual:
In the vertical columns, we have the particular skills and expertise that we are looking for right now. We expect new board members to have at least one of these skills.
The horizontal lines speaks to things that every board member should have. For instance, to be a board member, you should have to have some cultural sense of Mozilla. They are a set of things that are important for every candidate. In addition, there is a set of things that are important for the board as a whole. For instance, international experience. The board makeup overall should cover these areas.
The horizontal lines will not change too much over time, whereas the vertical lines will change, depending on who joins the Board and who leaves.
Finding the right people who match these criteria and who have the skills we need takes time. We hope to have extensive discussions with a wide range of people. Board candidates will meet the existing board members, members of the management team, individual contributors and volunteers. We see this as a good way to get to know how someone thinks and works within the framework of the Mozilla mission. It also helps us feel comfortable including someone at this senior level of stewardship.
We want your suggestions
We are hoping to add three new members to the Mozilla Foundation Board of Directors over the next 18 months. If you have candidates that you believe would be good board members, send them to msurman@mozillafoundation.org. We will use real discretion with the names you send us.
A couple of weeks ago the Localization Team at Mozilla released the Fluent Syntax specification. As mentioned in our announcement, we already have over 3000 Fluent strings in Firefox. You might wonder how we introduced Fluent to a running project. In this post I’ll detail on how the design of Fluent plays into that effort, and how we pulled it off.
Fluent’s Design for Simplicity
Fluent abstracts away the complexities of human languages from programmers. At the same time, Fluent makes easy things easy for localizers, while making complex things possible.
When you migrate a project to Fluent, you build on both of those design principles. You will simplify your code, and move the string choices from your program into the Fluent files. Only then you’ll expose Fluent to localizers to actually take advantage of the capabilities of Fluent, and to perfect the localizations of your project.
Fluent’s Layered Design
When building runtime implementations, we created several layers to tightly own particular tasks.
Fluent source files are parsed into Resources.
Multiple resources are aggregated in Bundles, which expose APIs to resolve single strings. Message and Term references resolve inside Bundles, but not necessarily inside Resources. A Bundle is associated with a single language, as well as fallback languages for i18n libraries.
Language negotiation and language fallback happen in the Localization level. Here you’d implement that someone looking for Frisian would get a Frisian string. If that’s missing or has a runtime problem, you might want to try Dutch, and then English.
Bindings use the Localization API, and integrate it into the development stack. They marshal data models from the programming language into Fluent data models like strings, numbers, and dates. Declarative bindings also apply the localizations to the rendered UI.
Invest in Bindings
Bindings integrate Fluent into your development workflow. For Firefox, we focused on bindings to generate localized DOM. We also have bindings for React. These bindings determine how fluent Fluent feels to developers, but also how much Fluent can help with handling the localized return values. To give an example, integrating Fluent into Android app development would probably focus on a LayoutInflator. In the bindings we use at Mozilla, we decided to localize as close to the actual display of the strings as possible.
If you have declarative UI generation, you want to look into a declarative binding for Fluent. If your UI is generated programmatically, you want a programmatic binding.
The Localization classes also integrate IO into your application runtime, and making the right choices here has strong impact on performance characteristics. Not just on speed, but also the question of showing untranslated strings shortly.
Migrate your Code
Migrating your code will often be a trivial change from one API to another. Most of your code will get a string and show it, after all. You might convert several different APIs into just one in Fluent, in particular dedicated plural APIs will go away.
You will also move platform-specific terminology into the localization side, removing conditional code. You should also be able to stop stitching several localized strings together in your application logic.
As we’ll go through the process here, I’ll show an example of a sentence with a link. The project wants to be really sure the link isn’t broken, so it’s not exposed to localizers at all. This is shortened from an actual example in Firefox, where we link to our privacy policy. We’ll convert to DOM overlays, to separate localizable and non-localizable aspects of the DOM in Fluent. Let’s just look at the HTML code snippet now, and look at the localizations later.
Last but not least, we’ll want to migrate the localizations. While migrating code is work, losing all your existing localizations is just outright a bad idea.
For our work on Firefox, we use a Python package named fluent.migrations. It’s building on top of the fluent.syntax package, and programmatically creates Fluent files from existing localizations.
It allows you to copy and paste existing localizations into a Fluent string for the most simple cases. It also concats several strings into a single result, which you used to do in your code. For these very simple cases, it even uses Fluent syntax, with specialized global functions to copy strings.
Then there are a bit more complicated tasks, notably involving variable references. Fluent only supports its built-in variable placement, so you need to migrate away from printf and friends. That involves firstly normalizing the various ways that a printf parameter can be formatted and placed, and then the code can do a simple replacement of the text like %2$S with a Fluent variable reference like {user-name}.
We also have logic to read our Mozilla-specific plural logic from legacy files, and to write them out as select-expressions in Fluent, with a variant for each plural form.
These transforms are implemented as pseudo nodes in a template AST, which is then evaluated against the legacy translations and creates an actual AST, which can then be serialized.
Concluding our example, before:
<ENTITY msg-start "This is a link to an ">
<ENTITY msg-middle "example">
<ENTITY msg-end ".">
After:
msg = This is a link to an <a data-l10n-name="msg-link">example</a> site.
Find out more about this package and its capabilities in the documentation.
Given that we’re OpenSource, we also want to carry over attribution. Thus our code not only migrates all the data, but also splits the migration into individual commits, one for each author of the migrated translations.
Once the baseline is migrated, localizers can dive in and improve. They can then start using parameterized Terms to adjust grammar, for example. Or add a plural form where English didn’t need one. Or introduce a platform-specific terminology that only exists in their language.
Gerv was Mozilla’s first intern. He arrived in the summer of 2001, when Mozilla staff was still AOL employees. It was a shock that AOL had allocated an intern to the then-tiny Mozilla team, and we knew instantly that our amazingly effective volunteer in the UK would be our choice.
When Gerv arrived a few things about him jumped out immediately. The first was a swollen, shiny, bright pink scar on the side of his neck. He quickly volunteered that the scar was from a set of surgeries for his recently discovered cancer. At the time Gerv was 20 or so, and had less than a 50% chance of reaching 35. He was remarkably upbeat.
The second thing that immediately became clear was Gerv’s faith, which was the bedrock of his response to his cancer. As a result the scar was a visual marker that led straight to a discussion of faith. This was the organizing principle of Gerv’s life, and nearly everything he did followed from his interpretation of how he should express his faith.
Eventually Gerv felt called to live his faith by publicly judging others in politely stated but damning terms. His contributions to expanding the Mozilla community would eventually become shadowed by behaviors that made it more difficult for people to participate. But in 2001 all of this was far in the future.
Gerv was a wildly active and effective contributor almost from the moment he chose Mozilla as his university-era open source project. He started as a volunteer in January 2000, doing QA for early Gecko builds in return for plushies, including an early program called the Gecko BugAThon. (With gratitude to the Internet Archive for its work archiving digital history and making it publicly available.)
Gerv had many roles over the years, from volunteer to mostly-volunteer to part-time, to full-time, and back again. When he went back to student life to attend Bible College, he worked a few hours a week, and many more during breaks. In 2009 or so, he became a full time employee and remained one until early 2018 when it became clear his cancer was entering a new and final stage.
Gerv’s work varied over the years. After his start in QA, Gerv did trademark work, a ton of FLOSS licensing work, supported Thunderbird, supported Bugzilla, Certificate Authority work, policy work and set up the MOSS grant program, to name a few areas. Gerv had a remarkable ability to get things done. In the early years, Gerv was also an active ambassador for Mozilla, and many Mozillians found their way into the project during this period because of Gerv.
Gerv’s work life was interspersed with a series of surgeries and radiation as new tumors appeared. Gerv would methodically inform everyone he would be away for a few weeks, and we would know he had some sort of major treatment coming up.
Gerv’s default approach was to see things in binary terms — yes or no, black or white, on or off, one or zero. Over the years I worked with him to moderate this trait so that he could better appreciate nuance and the many “gray” areas on complex topics. Gerv challenged me, infuriated me, impressed me, enraged me, surprised me. He developed a greater ability to work with ambiguity, which impressed me.
Gerv’s faith did not have ambiguity at least none that I ever saw. Gerv was crisp. He had very precise views about marriage, sex, gender and related topics. He was adamant that his interpretation was correct, and that his interpretation should be encoded into law. These views made their way into the Mozilla environment. They have been traumatic and damaging, both to individuals and to Mozilla overall.
The last time I saw Gerv was at FOSDEM, Feb 3 and 4. I had seen Gerv only a few months before in December and I was shocked at the change in those few months. Gerv must have been feeling quite poorly, since his announcement about preparing for the end was made on Feb 16. In many ways, FOSDEM is a fitting final event for Gerv — free software, in the heart of Europe, where impassioned volunteer communities build FLOSS projects together.
To memorialize Gerv’s passing, it is fitting that we remember all of Gerv — the full person, good and bad, the damage and trauma he caused, as well as his many positive contributions. Any other view is sentimental. We should be clear-eyed, acknowledge the problems, and appreciate the positive contributions. Gerv came to Mozilla long before we were successful or had much to offer besides our goals and our open source foundations. As Gerv put it, he’s gone home now, leaving untold memories around the FLOSS world.
The art of localizing a piece of software with a Yes button is to know what that button will do. This is an example of software UI that makes assumptions on language that hold for English, but might not for other languages. A more frequent example in both UI and languages that are affecting is piecing together text and UI controls:
In the localization tool, you’ll find each of those entries as individual strings. The localizer will recognize that they’re part of one flow, and will move fragments from the shared string to the drop-down as they need. Merely translating the individual segments is not going to be a proper localization of that piece of UI.
If we were to build a rule-based machine localization system, we’d find rules like
gaelic-yes:
If the title of your dialog contains a verb, localize Yes by translating the found verb.
pieced-ui:
For each variant,
Piece together the fragments of English to a single sentence
Translate the sentences into the target language
Find shared content in matching positions to the original layout
Split each translated fragment, and adjust the casing and spacing
Map the subfragments to the localization of the English individual fragments
Map the shared fragment to the localization of the English shared fragment
Now that’s rule-based, and it’d be tedious to maintain these rules. Neural Machine Translation (NMT) has all the buzz now, and Machine Learning in general. There is plenty of research that improves how NMT systems learn about the context of the sentence they’re translating. But that’s all text.
It’d be awesome if we could bring Software Analysis into the mix, and train NMT to localize software instead of translating fragments.
For Firefox, could one train on English and localized DOM? For Android’s XML layout, a similar approach could work? For projects with automated screenshots, could one train on those? Is there enough software out there to successfully train a neural network?
Do you know of existing research in this direction?
This week I had the opportunity to share Mozilla’s vision for an Internet that is open and accessible to all with the audience at MWC Americas.
I took this opportunity because we are at a pivotal point in the debate between the FCC, companies, and users over the FCC’s proposal to roll back protections for net neutrality. Net neutrality is a key part of ensuring freedom of choice to access content and services for consumers.
Earlier this week Mozilla’s Heather West wrote a letter to FCC Chairman Ajit Pai highlighting how net neutrality has fueled innovation in Silicon Valley and can do so still across the United States.
The FCC claims these protections hamper investment and are bad for business. And they may vote to end them as early as October. Chairman Pai calls his rule rollback “restoring internet freedom” but that’s really the freedom of the 1% to make decisions that limit the rest of the population.
At Mozilla we believe the current rules provide vital protections to ensure that ISPs don’t act as gatekeepers for online content and services. Millions of people commented on the FCC docket, including those who commented through Mozilla’s portal that removing these core protections will hurt consumers and small businesses alike.
Mozilla is also very much focused on the issues preventing people coming online beyond the United States. Before addressing the situation in the U.S., journalist Rob Pegoraro asked me what we discovered in the research we recently funded in seven other countries into the impact of zero rating on Internet use:
(Video courtesy: GSMA)
If you happen to be in San Francisco on Monday 18th September please consider joining Mozilla and the Internet Archive for a special night: The Battle to Save Net Neutrality. Tickets are available here.
You’ll be able to watch a discussion featuring former FCC ChairmanTom Wheeler; RepresentativeRo Khanna; Mozilla Chief Legal and Business OfficerDenelle Dixon;Amy Aniobi, Supervising Producer, Insecure (HBO);Luisa Leschin, Co-Executive Producer/Head Writer, Just Add Magic (Amazon);Malkia Cyril, Executive Director of the Center for Media Justice; andDane Jasper, CEO and Co-Founder of Sonic. The panel will be moderated byGigi Sohn, Mozilla Tech Policy Fellow and former Counselor to Chairman Wheeler. It will discuss how net neutrality promotes democratic values, social justice and economic opportunity, what the current threats are, and what the public can do to preserve it.
I’m going to just recreate blame, he said. It’s going to be easy, he said.
We have a project to migrate the localization of Firefox to one repository for all channels, nick-named cross-channel, or x-channel in short. The plan is to create one repository that holds all the en-US strings we need for Firefox and friends on all channels. One repository to rule them all, if you wish. So you need to get the contents of mozilla-central, comm-central, *-aurora, *-beta, *-release, and also some of *-esr?? together in one repository, with, say, one toolkit/chrome/global/customizeToolbar.dtd file that has all the strings that are used by any of the apps on any branch.
We do have some experience with merging the content of localization files as part of l10n-merge which is run at Firefox build time. So this shouldn’t be too hard, right?
Enter version control, and the fact that quite a few of our localizers are actually following the development of Firefox upstream, patch by patch. That they’re trying to find the original bug if there’s an issue or a question. So, it’d be nice to have the history and blame in the resulting repository reflect what’s going on in mozilla-central and its dozen siblings.
Can’t we just hg convert and be done with it? Sadly, that only converts one DAG into another hg DAG, and we have a dozen. We have a dozen heads, and we want a single head in the resulting repository.
Thus, I’m working on creating that repository. One side of the task is to update that target repository as we see updates to our 12 original heads. I’m pretty close to that one.
The other task is to create a good starting point. Or, good enough. Maybe if we could just create a repo that had the same blame as we have right now? Like, not the hex or integer revisions, but annotate to the right commit message etc? That’s easy, right? Well, I thought it was, and now I’m learning.
To understand the challenges here, one needs to understand the data we’re throwing at any algorithm we write, and the mercurial code that creates the actual repository.
As of FIREFOX_AURORA_45_BASE, just the blame for the localized files for Firefox and Firefox for Android includes 2597 hg revisions. And that’s not even getting CVS history, but just what’s in our usual hg repository. Also, not including comm-central in that number. If that history was linear, things would probably be pretty easy. At least, I blame the problems I see in blame on things not being linear.
So, how non-linear is that history. The first attempt is to look at the revision set with hg log -G -r .... . That creates a graph where the maximum number of parents of a single changeset is at 1465. Yikes. We can’t replay that history in the target repository, as hg commits can only have 2 parents. Also, that’s clearly not real, we’ve never had that many parallel threads of development. Looking at the underlying mercurial code, it’s showing all reachable roots as parents of a changeset, if you have a sparse graph. That is, it gives you all possible connections through the underlying full graph to the nodes in your selection. But that’s not what we’re interested in. We’re interested in the graph of just our nodes, going just through our nodes.
In a first step, I wrote code that removes all grandchildren from our parents. That reduces the maximum number of parents to 26. Much better, but still bad. At least it’s at a size where I can start to use graphviz to create actual visuals to inspect and analyze. Yes, I can graph that graph.
The resulting graph has a few features that are actually already real. mozilla-central has multiple roots. One is the initial hg import of the Firefox code. Another is including Firefox for Android in mozilla-central, which used to be an independent repository. Yet another is the merge of services/sync. And then I have two heads, which isn’t much of a problem, it’s just that their merge commit didn’t create anything to blame for, and thus doesn’t show up in my graph. Easy to get to, too.
Looking at a subset of the current graph, it’s clear that there are more arcs to remove:
Anytime you have an arc that just leap-frogs to an ancestor, you can safely remove that. I indicated some in the graph above, and you’ll find more – I was just tired of annotating in Preview. As said before, I already did that for grandchildren. Writing this post I realize that it’s probably easy enough to do it for grandgrandchildren, too. But it’s also clear from the full graph, that that algorithm probably won’t scale up. Seems I need to find a good spot at which to write an explicit loop detection.
This endeavour sounds a bit academic at first, why would you care? There are two reasons:
Blame in mercurial depends on the diff that’s stored in the backend, and the diff depends on the previous content. So replaying the blame in some way out of band doesn’t actually create the same blame. My current algorithm is to just add the final lines one by one to the files, and commit. Whitespace and reoccurring lines get all confused by that algorithm, sadly.
Also, this isn’t a one-time effort. The set of files we need to expose in the target depends on the configuration, and often we fix the configuration of Firefox l10n way after the initial landing of the files to localize. So having a sound code-base to catch up on missed history is an important step to make the update algorithm robust. Which is really important to get it run in automation.
PS: The tune for this post is “That Smell” by Lynyrd Skynyrd.
Or, how to change everything and nobody sees a difference.
Heads up: All I’m writing about here is running on non-web-facing VMs behind VPN.
tl;dr: I changed 5 VMs, landed 76 changesets in 7 repositories, resolving 12 bugs, got two issues in docker fixed, and took a couple of days of downtime. If automation is your cup of tea, I have some open questions at the end, too.
To set the stage: Behind the scenes of the elmo website, there’s a system that generates the data that it shows. That system consists of two additional VMs, which help with the automation.
One is nick-named a10n, and is responsible for polling all those mercurial repositories that we use for l10n, and to update the elmo database with information about these repositories as it comes in. elmo basically keeps a copy of the mercurial metadata for quicker access.
The other is running buildbot to do the actual data collection jobs about the l10n status in our source repositories. This machine runs both a master and one slave (the actual workhorse, not my naming).
This latter machine is an old VM, on old OS, old Python (2.6), never had real IT support, and is all around historic. And needed to go.
With the help of IT, I had a new VM, with a new shiny python 2.7.x, and a new storage. Something that can actually run current versions of compare-locales, too. So I had to create an update for
At the same time, we also changed hg.m.o from http to https all over the place, which also required a handful of code changes.
One thing that I did not change is buildbot. I’m using a heavily customized version of buildbot 0.7.12, which is incompatible with later buildbot changes. So I’m tied to my branch of 0.7.12 for now, and with that to Twisted 8.2.0. That will change, but in a different blog post.
Unified Repositories
One thing I wanted and needed for a long time was to use unified clones of our mercurial repositories. Aside from the obvious win in terms of disk usage, it allows to use mercurial directly to create a diff from a revision that’s only on aurora against a revision that’s only on beta. Sadly, I did think otherwise when I wrote the first parts of elmo and the automation behind it, often falling back to default instead of an actual hash revision, if I didn’t know anything ad-hoc. So that had to go, and required a surprising amount of changes. I also changed the way that comparisons are triggered, making them fully reproducible. They also got more robust. I used to run hg id -ir . to get the revision, which worked OK, unless you had extension errors in stdout/stderr. Meh. Good that that’s gone.
As I noted, the unified repositories also benefit doing diffs, which is one of the features of elmo for reviewing localizations. Now that we can just use plain mercurial to get those diffs, I could remove a bunch of code that created diffs between aurora and beta by creating diffs between each head and some ancestor, and then sticking those diffs back together. Good that that’s gone.
Testing
Testing an automation with that many moving parts is hard. Some things can be tested via unit tests, but more often, you just need integration tests. I still have to find a way to write automated integration tests, but even manual integration tests require a ton of set-up:
elmo
MySQL
ElasticSearch
RabbitMQ
Mercurial upstream repositories
Mercurial web server
a10n get-pushes poller
a10n data ingestion worker
Buildbot master
Buildbot slave
Doing this manually is evil, and on Macs, it’s not even possible, because Twisted 8.2.0 doesn’t build anymore. I used to have a script that did many of these things, but that’s …. you guessed it. Good that that’s gone. Now I have a docker-composetest setup, that has most things running with just a docker-compose up. I’m still running elmo and MySQL on my host machine, fixing that is for another day. Also, I haven’t found a good way to do initial project setup like database creations. Anyway, after finding a couple of bugs in docker, this system now fires up quickly and let’s me do various changes and see how they pass through the system. One particularly nice artifact is that the output of docker-compose is actually all the logs together in one stream. So as you’re pushing things through the system, you just have one log to watch.
As part of this work, I also greatly simplified the code structure, and moved the buildbot integration from three repositories into one. Good that those are gone.
snafus
Sadly there were a few bits and pieces where my local testing didn’t help:
Changing the URL schemes for hg.m.o to https alongside this change triggered a couple of problems where Twisted 8.2 and modern Python/OpenSSL can’t get a connection up. Had to replace the requests to websites with synchronous urllib2.urlopen calls.
Installing mercurial in a virtualenv to be used via hglib is good, but WSGI doesn’t activate the virtualenv, and thus PATH isn’t set. My fix still needs some server-side changes to work.
I didn’t have enough local testing for the things that Thunderbird needs. That left that setup burning for longer than I anticipated. The fix wasn’t hard, just badly timed.
Every now and then, Django 1.8.x and MySQL decide that it’s a good idea to throw away the connection, and die badly. In the case of long-running automation jobs, that’s really hard to prevent, in particular because I still haven’t fully understood what change actually made that happen, and what the right fix is. I just plaster connection.close() into every other function, and see if it stops dying.
On Saturday morning I woke up, and the automation didn’t process Firefox for a locale on aurora. I freaked out, and added tons of logging. Good logging that is. Best logging. Found a different bug. Also found out that the locale was Belarus, and that wasn’t part of the build on Saturday. Hit my head against a wall or two.
Said logging made uncaught exceptions in some parts of the code actually show up in logs, and discovered that I hadn’t tested my work against bad configurations. And we have that, Thunderbird just builds everything on central, regardless of whether the repositories it should use for that exist or not. I’m not really happy yet with the way I fixed this.
Open Questions
Anyone got taskcluster running on something resembling docker-compose for local testing and development? You know, to get off of buildbot.
Initial setup steps for the docker-compose staging environment are best done … ?
Test https connections in docker-compose? Can I? Which error cases would that cover?
I’ve given the team pages on l10n.mozilla.org a good whack in the past few days. Time to share some details and get feedback before I roll it out.
The gist of it: More data in less screen space, I just folded things into rows, and made the rows slimmer. Better display of sign-off status, I separated status from progress and actions. Actions are now ordered chronologically, too.
The details? Well, see my recording where I walk you through:
You can select branches of products, as well as the localizations you’re interested in, and get data you want.
Say you’re looking for mobile and India. You’d want Firefox OS and Firefox for Android aka Fennec. The latter is actively localized on aurora, so you’d want the gaia tree and fennec_aurora. You want Assamese, Bengali, Gujarati…. and 9 other languages. Select gu and pa, too, ’cause why not.
Or are you keen on Destop in Latin America? Again we’re looking at Aurora, so fx_aurora is our tree of choice this time. Locales are Spanish in its American Variants, and Brazilian Portuguese.
Select generously, you can always reduce your selection through the controls on the right side of the resulting dashboard.
Play around, and compare the Status and History columns. Try to find stories, and share them in the comments below.
A bit more details on fx-aurora vs Firefox 32. Right now, Firefox 32 is on the Aurora channel and repository branch. Thus, selecting either gives you the same data today. In six weeks, though, 32 is going to be on beta, so if you bookmark a link, it’d give you different data then. That’s why you can only select one or the other.
Team pages and the project overview tables now contain sparklines, indicating the progress over the past 50 days.
Want to see how a localization team is doing? Now with 100% more self-serve.
If the sparklines go up like so
the localization is making good progress. Each spark is an update (either en-US or the locale), so sparks going up frequently show that the team is actively working on this one.
If the sparklines are more like
then, well, not so much.
The sparklines always link to an interactive page, where you can get more details, and look at smaller or larger time windows for that project and that locale.
You should also look at the bugzilla section. A couple of bugs with recent activity is good. More bugs with no activity for a long time, not so much.
Known issues: We still have localizations showing status for central/nightly, even though those teams don’t work on central. Some teams do, but not all. Also, the sparklines start at some point in the past 50 days, that’s because we don’t figure out the status before. We could.
Or, how I made converting gaia to gaia-l10n suck less.
Background: For Firefox OS, we’re exposing a modified repository to localizers, so that it’s easier to find out what to work on, and to get support from the l10n dashboards. Files in the main gaia repository on github like
We’re also not supporting git on the l10n dashboard yet, so we need hg repositories.
I haven’t come across a competitor to hg convert on the git side yet, so I looked on the mercurial side of life. I started by glancing of the code in hgext/convert in the upstream mercurial code. That does a host of things to get parents and graphs right, and I didn’t feel like replicating that. It doesn’t offer hooks for dynamic file maps, though, let alone content rewriting. But it’s python, and it’s open-source. So I forked it.
With hg convert. Isn’t that meta? That gives me a good path to update the extension with future updates to upstream mercurial. I started out with a conversion of mercurial 2.7.1, then removed all the stuff I don’t need like bzr support etc. Then I made the mercurial code do what I need for gaia. I had to disable some checks that try to avoid commits that don’t actually change the contents, because I don’t mind that happening. And last but not least I added the filemap and the shamap of the initial conversion of hgext/convert, so that future updates don’t depend on my local disk.
Now I could just run hg gaiaconv and get what I want. Enter the legacy repositories for en-US. We only want fast-forward merges in hg, and in the conversion to git. No history editing allowed. But as you can probably guess, the new history is completely incompatible with the old, from changeset one. But I don’t mind, I hacked that.
I did run the regular hg gaiaconv up to the revision 21000 of the integration/gaia-central repository. That ended up with the graph for revision 4af36780fb5d.
Let me share some recent revelations I had. It all started with the infamous Berlin airport. Not the nice one in Tegel, but the BBI desaster. The one we’ve thought we’d open last year, and now we don’t know which year.
Part of the newscoverage here in Germany was all about how they didn’t do any risk analysis, and are doomed, and how that other project for the Olympics in London did do risk analysis, and got in under budget, ahead of time.
So what’s good for the Olympics can’t be bad for Firefox, and I started figuring out the math behind our risk to ship Firefox, at a given time, with loads of localizations. How likely is it that we’ll make it?
Interestingly enough, the same algorithm can also be applied to a set of features that are scheduled for a particular Firefox release. Locales, features, blockers, product-managers, developers, all the same thing :-). Any bucket of N things trying to make a single deadline have similar risks. And the same cure. So bear with me. I’ll sprinkle graphs as we go to illustrate. They’ll link to a site that I’ve set up to play with the numbers, reproducing the shown graphs.
The setup is like this: Every single item (localization, for exampe) has a risk, and I’m assuming the same risk across the board. I’m trying to do that N times, and I’m interested in how likely I’ll get all of them. And then I evaluate the impact of different amounts of freeze cycles. If you’re like me, and don’t believe any statistics unless they’re done by throwing dices, check out the dices demo.
Anyway, let’s start with 20% risk per locale, no freeze, and up to 100 locales.
Ouch. We’re crossing 50-50 at 3 items already, and anything at scale is a pretty flat zero-chance. Why’s that? What we’re seeing is an exponential decay, the base being 80%, and the power being how often we do that. This is revelation one I had this week.
How can we help this? If only our teams would fail less often? Feel free to play with the numbers, like setting the successrate from 80% to 90%. Better, but the system at large still doesn’t scale. To fight an exponential risk, we need a cure that’s exponential.
Turns out freezes are just that. And that’d be revelation two I had this week. Let’s add some 5 additional frozen development cycles.
Oh hai. At small scales, even just one frozen cycle kills risks. Three features without freeze have a 50-50 chance, but with just one freeze cycle we’re already at 88%, which is better than the risk of each individual feature. At large scales like we’re having in l10n, 2 freezes control the risk to mostly linear, 3 freezes being pretty solid. If I’m less confident and go down to 70% per locale, 4 or 5 cycles create a winning strategy. In other words, for a base risk of 20-30%, 4-5 freeze cycles make the problem for a localized release scale.
It’s actually intuitive that freezes are (kinda) exponentially good. The math is a tad more complicated, but simplified, if your per-item success rate is 70%, you only have to solve your problem for 30% of your items in the next cycle, and for 9% in the second cycle. Thus, you’re fighting scale with scale. You can see this in action on the dices demo, which plays through this each time you “throw” the dices.
Now onwards to my third revelation while looking at this data. Features and blockers are just like localizations. Going in to the rapid release cycle with Firefox 5 etc, we’ve made two rules:
Feature-freeze and string-freeze are on migration day from central to aurora
Features not making the freeze take the next train
That worked fine for a while, but since then, mozilla has grown as an organization. We’ve also built out dependencies inside our organization that make us want particular features in particular releases. That’s actually a good situation to be in. It’s good that people care, and it’s good that we’re working on things that have organizational context.
But this changed the risks in our release cycle. We started off having a single risk of exponential scale after the migration date (l10n). Today, we have features going in to the cycle, and localizations thereof. At this point, having feature-freeze and string-freeze being the same thing becomes a risk for the release cycle at large. We should think about how to separate the two to mitigate the risk for each effectively, and ship awesome and localized software.
I learned quite a bit looking at our risks, I hope I could share some of that.
Language packs are add-ons that you can install to add additional localizations to our desktop applications.
Starting with tomorrow’s nightly, and thus following the Firefox 18 train, language packs will be restartless. That was bug 677092, landed as 812d0ba83175.
To change your UI language, you just need to install a language pack, set your language (*), and open a new window. This also works for updates to an installed language pack. Opening a new window is the workaround for not having a reload button on the chrome window.
The actual patch turned out to be one line to make language packs restartless, and one line so that they don’t try to call in to bootstrap.js. I was optimistic that the chrome registry was already working, and rightfully so. There are no changes to the language packs themselves.
Tests were tricky, but Blair talked me through most of it, thanks for that.
(*) Language switching UI is bug 377881, which has a mock-up for those interested. Do not be scared, it only shows if you have language packs installed.

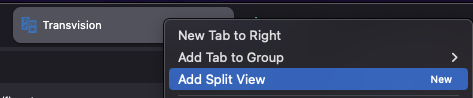
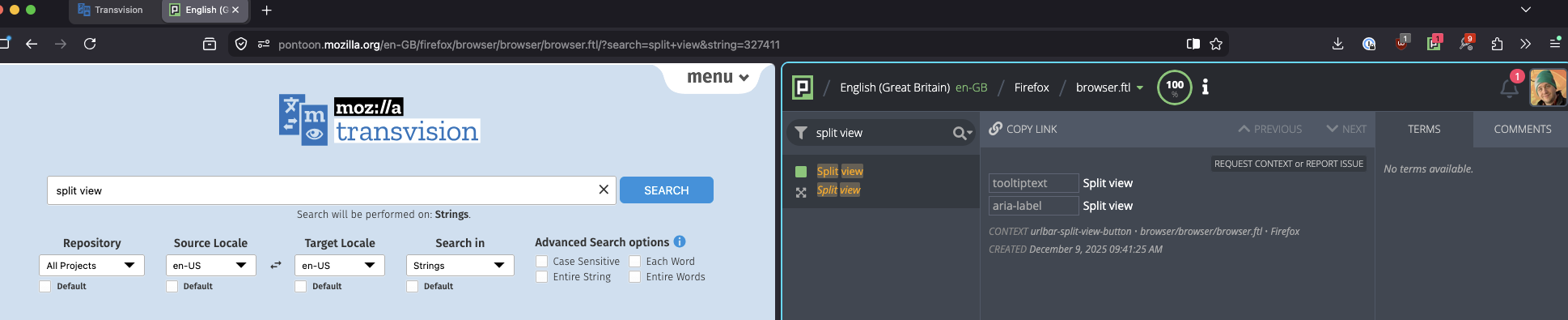








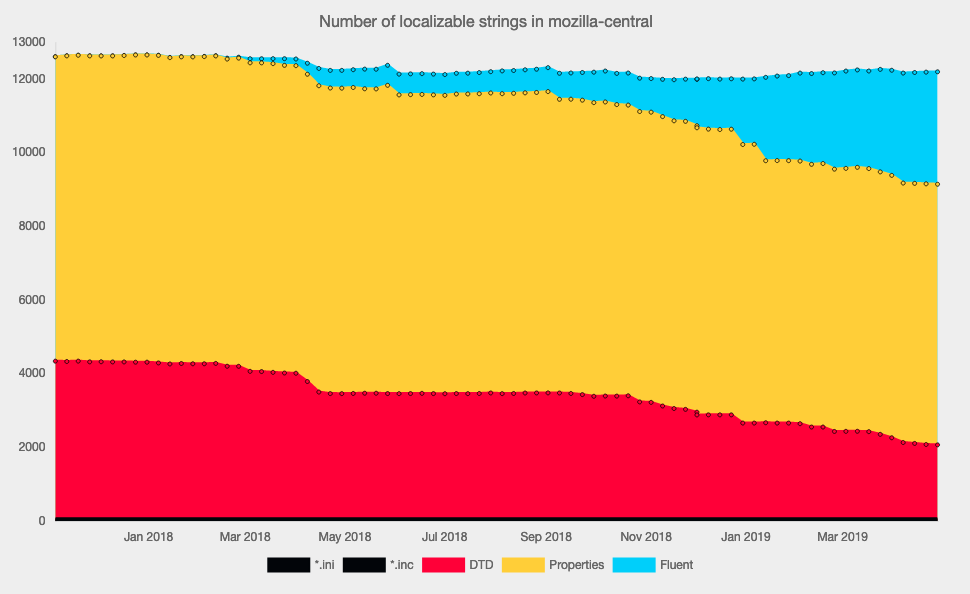




{kind=link}